


If you didn't read the previous part, we highly advise you to do that!
In the previous part we have discussed the pros and cons of serverless architectures, different serverless tools and technologies, integration patterns between serverless components and more.
In this part, we are going to discuss how we can decouple Lambda code and dependencies
continuous-integration from Terraform and delegate it to external CI services like Codebuild
and Codepipeline.
Why Lambda CI using Terraform is a bad and difficult approach?

There are many drawbacks when using Terraform to continuously integrate new lambda code/dependencies changes:
❌ From a structural perspective: it is considered a bad practice to mix business logic (code) and packages
(dependencies) with Terraform HCL files in the same codebase, because the engineering team building lambda code should
not worry about cloning the infrastructure repository and committing to it. On the other hand, the DevOps team should
have a clean Terraform codebase without any business logic.
❌ From an infrastructure CI perspective: if your DevOps team is using Terraform Cloud for infrastructure CI, each
time a backend engineer pushes a new commit to Lambda code, Terraform Cloud will have to start plan/apply runs, and if
the lambda code is actively updated, for example the Lambda is an API and the engineering team is updating it many times
during the day, this will slow down Terraform Cloud runs queue as terraform can only have one active run per workspace,
and, eventually, the DevOps team will be frustrated because they will have to wait for the runs to finish.
❌ No way to support releases: you can't have a QA Lambda which is updated on merges to master, and a
Production Lambda which is updated if a tag/release is created, because the lambda is not version controlled on its own
git repository, and it is part of the infrastructure repository.
❌ No proper way to build lambda application dependencies: if the package's descriptor changed, there is no way to
build and publish the dependencies again and the process should be done manually each time there is a change.
❌ For compatibility: Lambda application dependencies should be built using a runtime similar to the actual Lambda
runtime, and even worse than that, if you decide to build dependencies using Terraform Cloud, you can't. because you
don't have control over terraform instances, and you don't know if a specific nodejs or python version is already
installed.
What are we trying to achieve?

Before we start implementing the solution we should agree on the set of capabilities the solution must adhere to:
✅ Support famous runtimes: The CI process should be able to support at least the two famous lambda runtimes
python and nodejs.
✅ Support custom packages: installing custom packages that does not exist in Lambda runtime passed to CI process
as a package's descriptor file path in git repository. packages.json or requirements.txt.
✅ Caching: the integration/deployment process should be fast thanks to code and dependencies caching.
✅ Resiliency: during deployment, the process should not break the currently published version and traffic
shifting between the current and new deployment should be seamless.
✅ Compatibility: Lambda dependencies packages should be built in a sandboxed local environment that replicates
the live AWS Lambda environment almost identically – including installed software and libraries.
✅ Loose coupling: Lambda code should be decoupled entirely from Terraform.
✅ Interoperability: The CI process should be able to deploy Lambdas versioned in github repositories.
✅ Support mono-repos: The solution should be able to support mono-repos and dedicated repos, so all lambdas can
be placed in a single git repositories, or it can be versioned in a dedicated repository.
✅ Alerts: The CI pipeline should notify the failure or success of the process through slack.
Prepare terraform to delegate CI to codepipeline/codebuild

In order to delegate Lambda CI to codepipeline and codebuild, we should decouple lambda code and dependencies from terraform resources.
Lambda dummy code package
The first thing we need to do is providing a dummy code package to Terraform Lambda resource and instructing
Terraform to ignore any changes affecting s3_key, s3_bucket, layers and filename as they will be
changed by the CI process and we don't want Terraform to revert those changes on every deployment.
In other words, the external CI process will say to terraform: Don't worry about code or dependencies, I will take care of that
data "archive_file" "dummy" {
output_path = "${path.module}/dist.zip"
type = "zip"
source {
content = "dummy dummy"
filename = "dummy.txt"
}
}
resource "aws_lambda_function" "function" {
function_name = local.prefix
publish = true
role = aws_iam_role.role.arn
# runtime
runtime = var.runtime
handler = var.handler
# resources
memory_size = var.memory_size
timeout = var.timeout
# dummy package, package is delegated to CI pipeline
filename = data.archive_file.dummy.output_path
environment {
variables = var.envs
}
tags = merge(
local.common_tags,
map(
"description", var.description
)
)
# LAMBDA CI is done through codebuild/codepipeline
lifecycle {
ignore_changes = [s3_key, s3_bucket, layers, filename]
}
}
The dummy package we have created and provided to Lambda resource is important, because during Lambda resource creation Terraform will not be able to create the Lambda function without a code package.
We also added a lifecycle ignore_changes meta-argument instructing terraform to ignore changes to code
[s3_key, s3_bucket, filename] and dependencies [layers].
Lambda alias
A Lambda alias is like a pointer to a specific function version. We can access the function version using the alias
Amazon Resource Name (ARN). Since the Lambda version will be changed constantly, we need to create a latest
alias and on each deploy we have to update the alias with the new lambda version.
# Required by lambda provisioned concurrency
resource "aws_lambda_alias" "alias" {
name = "latest"
description = "alias pointing to the latest published version of the lambda"
function_name = aws_lambda_function.function.function_name
function_version = aws_lambda_function.function.version
lifecycle {
ignore_changes = [
description,
routing_config
]
}
}
The main advantage of Lambda alias is to avoid other resources depending on the lambda function from invoking a broken
lambda function version, and they will always invoke the latest stable version that the CI process have tagged with
latest alias at the end of the pipeline.
The other advantage is the ability for other services to invoke latest version without needing to update them
whenever the function version changes.
We can also specify routing configuration on an alias to send a portion of the traffic to a second function version. For example, we can reduce the risk of deploying a new version by configuring the alias to send most of the traffic to the existing version, and only a small percentage of traffic to the new version.
A lambda alias is required in case you want to implement provisioned concurrency afterwards.
Calling the module
We have prepared terraform-aws-codeless-lambda reusable terraform module for you here, you can call it like this
for creating Lambda functions ready for External CI:
module "lambda" {
source = "git::https://github.com/obytes/terraform-aws-codeless-lambda.git//modules/lambda"
prefix = "demo-api"
common_tags = {env = "test", stack = "demos"}
description = "Terraform is my creator but Codepipeline is the demon I listen to"
envs = {API_KEY = "not-secret"}
runtime = "python3.9"
handler = "app.handler"
timeout = 29
memory_size = 1024
policy_json = data.aws_iam_policy_document.policy.json
logs_retention_in_days = 14
}
The module will output the required attributes that will be used by CI process and by other components using/invoking the lambda, like API Gateway, etc.
output "lambda" {
value = {
name = aws_lambda_function.function.function_name
arn = aws_lambda_function.function.arn
runtime = aws_lambda_function.function.runtime
alias = aws_lambda_alias.alias.name
invoke_arn = aws_lambda_alias.alias.invoke_arn
}
}
CI Process Workflow

Before writing the CI script, we need to design the workflow of the process.

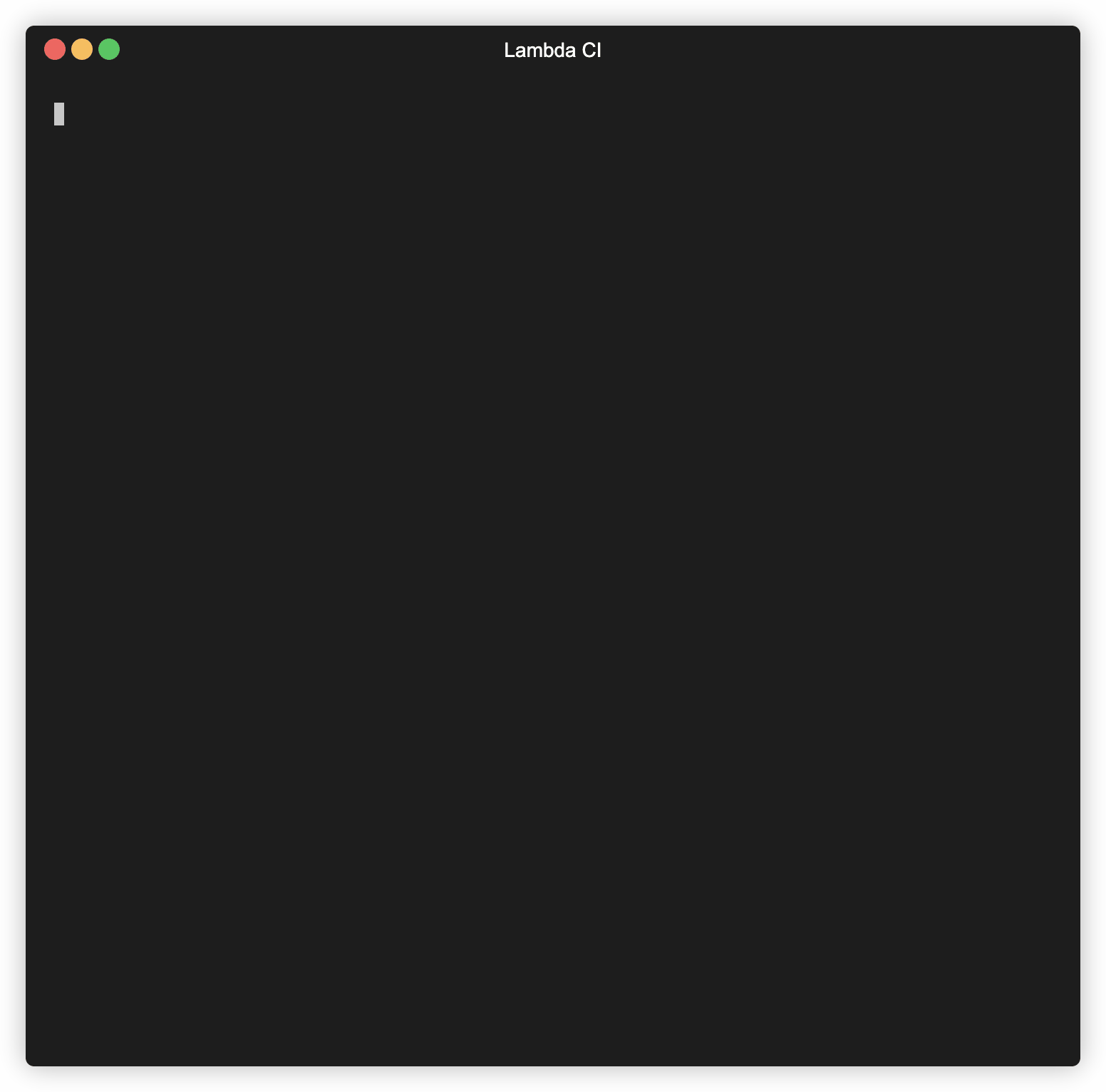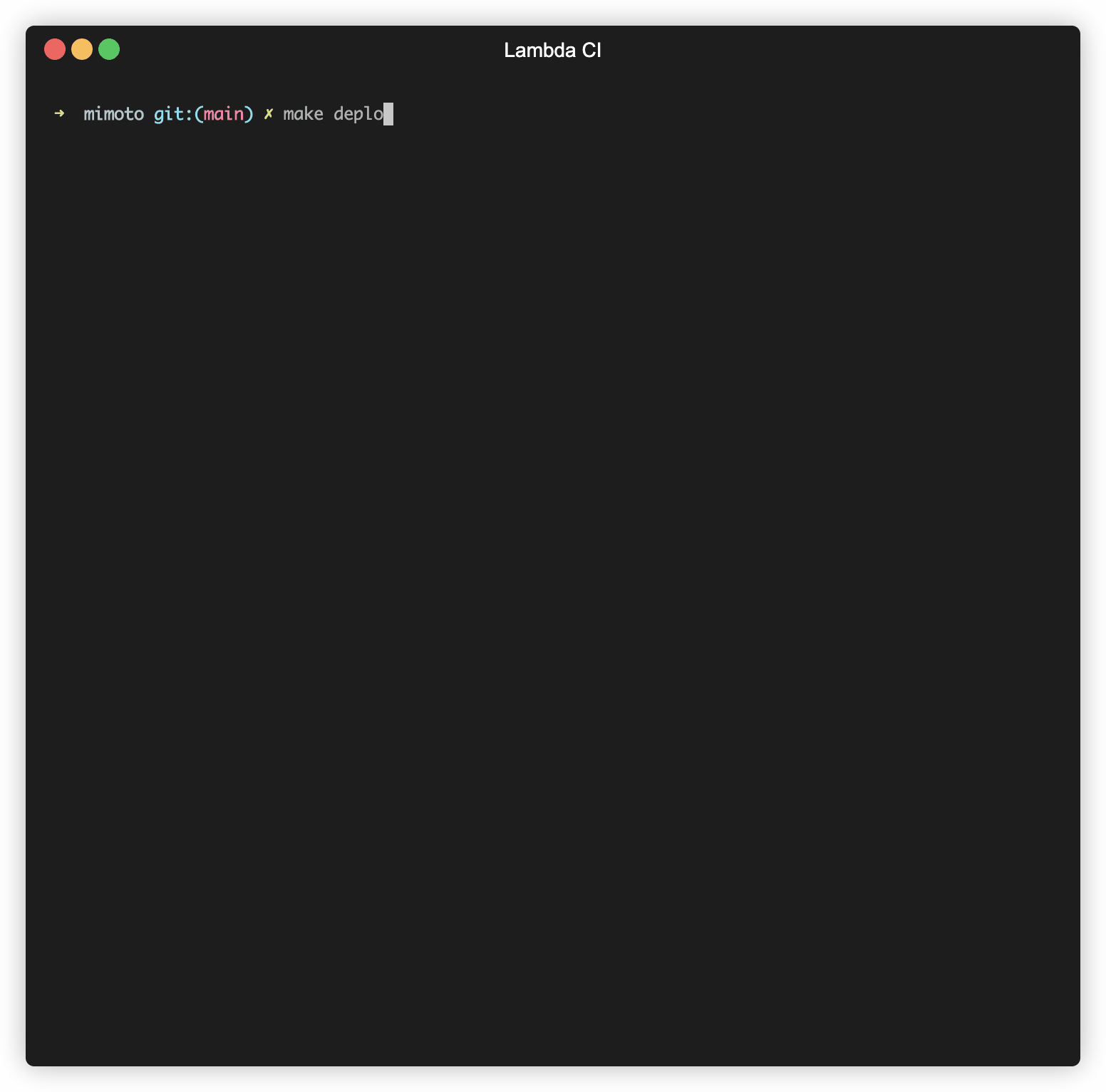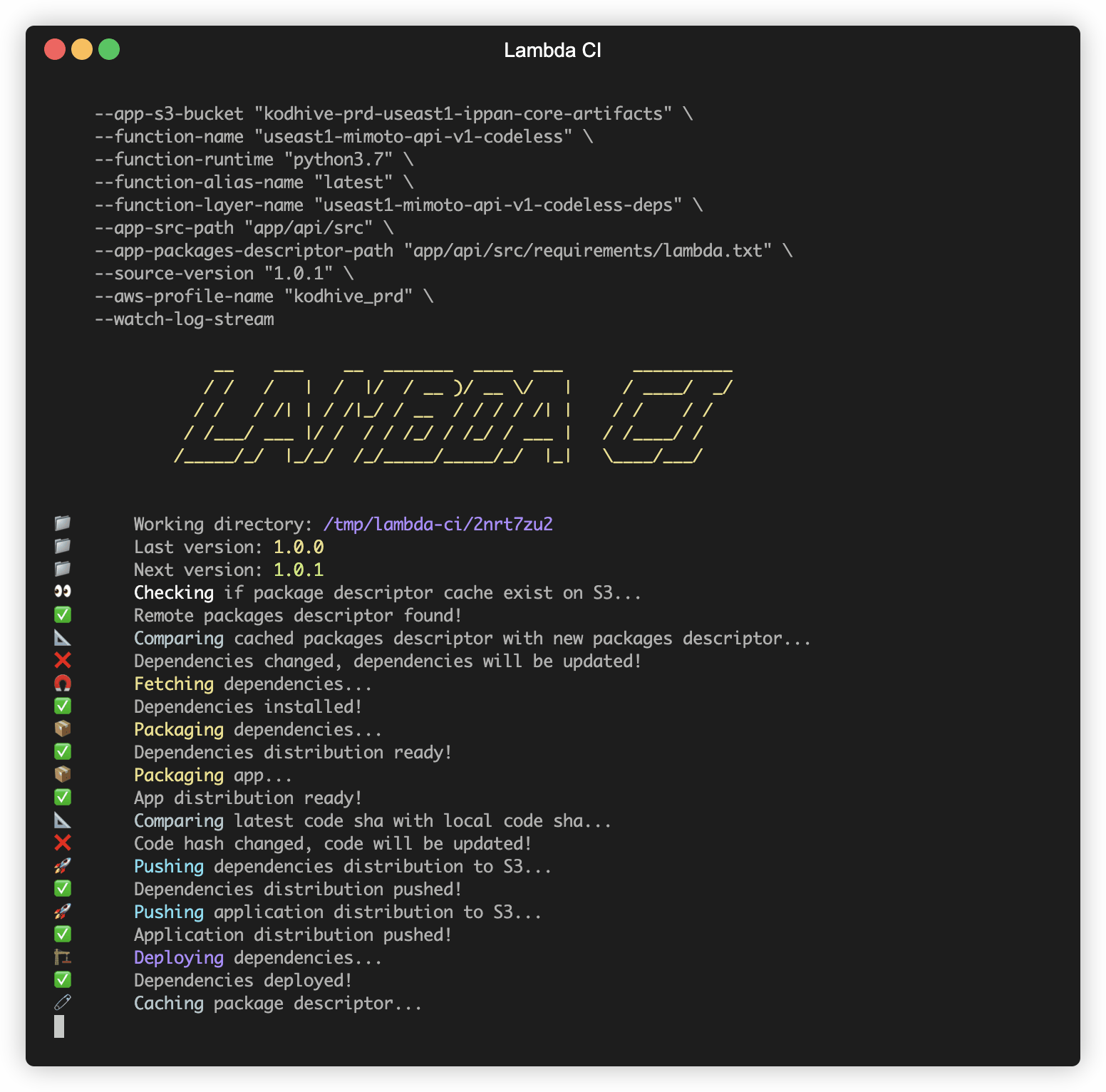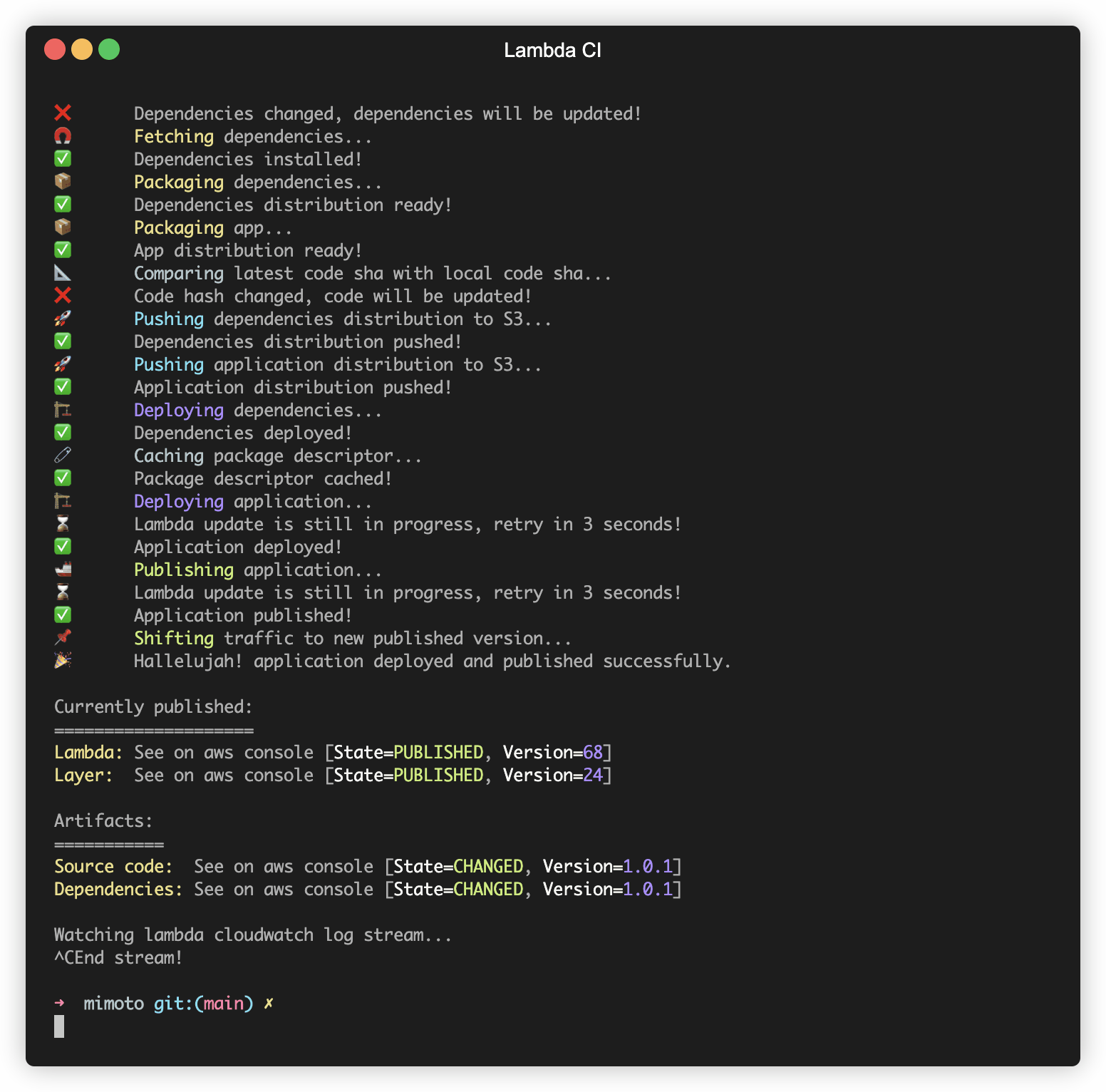
Check
In the first stage we checkout the new packages' descriptor, and check if the previous packages' descriptor exists in
S3, which is an edge case for the first execution. And if the package descriptor exists we need to download it for
next stage.
We also checkout the new application code and current source code hash that will be used in the next stage!
Bundle
If it is the first build we can jump directly and build/package the dependencies in the packages' descriptor
Otherwise, if it is not the first build, and the previous descriptor is already cached in S3, we will compare the previously cached descriptor with the new descriptor.
If they are not the same, then the descriptor is changed, and we will have to build and package the dependencies again, or else we can jump directly to the next stage.
Next, we package the new application source code, and we calculate its hash and compare it with the current source code hash. if they are different, then we have to push the new source code to S3.
For building lambda application dependencies we will use
lambci/lambdadocker image which is a sandboxed local environment that replicates the live AWS Lambda environment almost identically – including installed software and libraries.
Uploading artifacts
After building and packaging application code and/or dependencies, it's time to upload the packaged files to S3. we need to upload the artifacts in two different names:
- The first package should include the word
latestin the artifact name. - The second package should include the
commit digest hashin the artifact name.
The reason for this redundancy is to ensure we don't update the existing Lambda code with broken packages, so the previous lambda version will keep pointing to the previous code/dependencies, and the newer lambda version will point to the new code with the new commit digest hash as the artifact name.
This is an example of the files that will be uploaded to S3:
- APP version S3 KEY -
lambda-ci-demo/{hash}/app.zip - APP latest S3 KEY -
lambda-ci-demo/latest/app.zip - DEP version S3 KEY -
lambda-ci-demo/{hash}/deps.zip - DEP latest S3 KEY -
lambda-ci-demo/latest/deps.zip
AWS Lambda size limit is 50mb when you upload the code directly to the Lambda service. However, if the code deployment package size is more than that, we have an option to upload it to S3 and download it while triggering the function invocation. That's why we are going to use S3 to support large deployment packages.
Deploying dependencies and application
Now that we have the dependencies stored in S3, we can publish a new layer version that points to the new dependencies
with publish_layer_version(..) and update the lambda function to use the new layer version with
update_function_configuration(..).
After a successful deployment, we cache the new packages' descriptor in order for subsequent runs to be faster.
After that, we have to deploy the actual lambda code, so we update the Lambda function to point to the newer code
package in S3 using update_function_code(..).
Publishing application
Yes, we have deployed our Lambda function with newer dependencies and newer code but the services depending on it are
still pointing to the old Lambda function version tagged with latest alias, so we need to shift traffic to the
new version.
First, we should create a new lambda function version using publish_version(..) and then we have to update the
lambda alias to point to the newly created lambda version using update_alias(..).
Implementation
The stages in the above workflow are implemented in this package https://github.com/obytes/aws-lambda-ci and published
in a public PyPi repository, you can install it with pip:
pip3 install aws-lambda-ci
Local CI with standalone CI Script

In case you are still developing your function locally and you want to test it but you still don't have codebuild and
codepipeline resources in development environment, you can use aws-lambda-ci like this:
aws-lambda-ci \
--app-s3-bucket "demo-artifacts" \
--function-name "demo-api" \
--function-runtime "python3.9" \
--function-alias-name "latest" \
--function-layer-name "demo-api-deps" \
--app-src-path "src" \
--app-packages-descriptor-path "requirements.txt" \
--source-version "1.0.2" \
--aws-profile-name "kodhive_prd" \
--watch-log-stream
First usage will take a longer time, because it needs to pull
lambci/lambdafrom dockerhub.
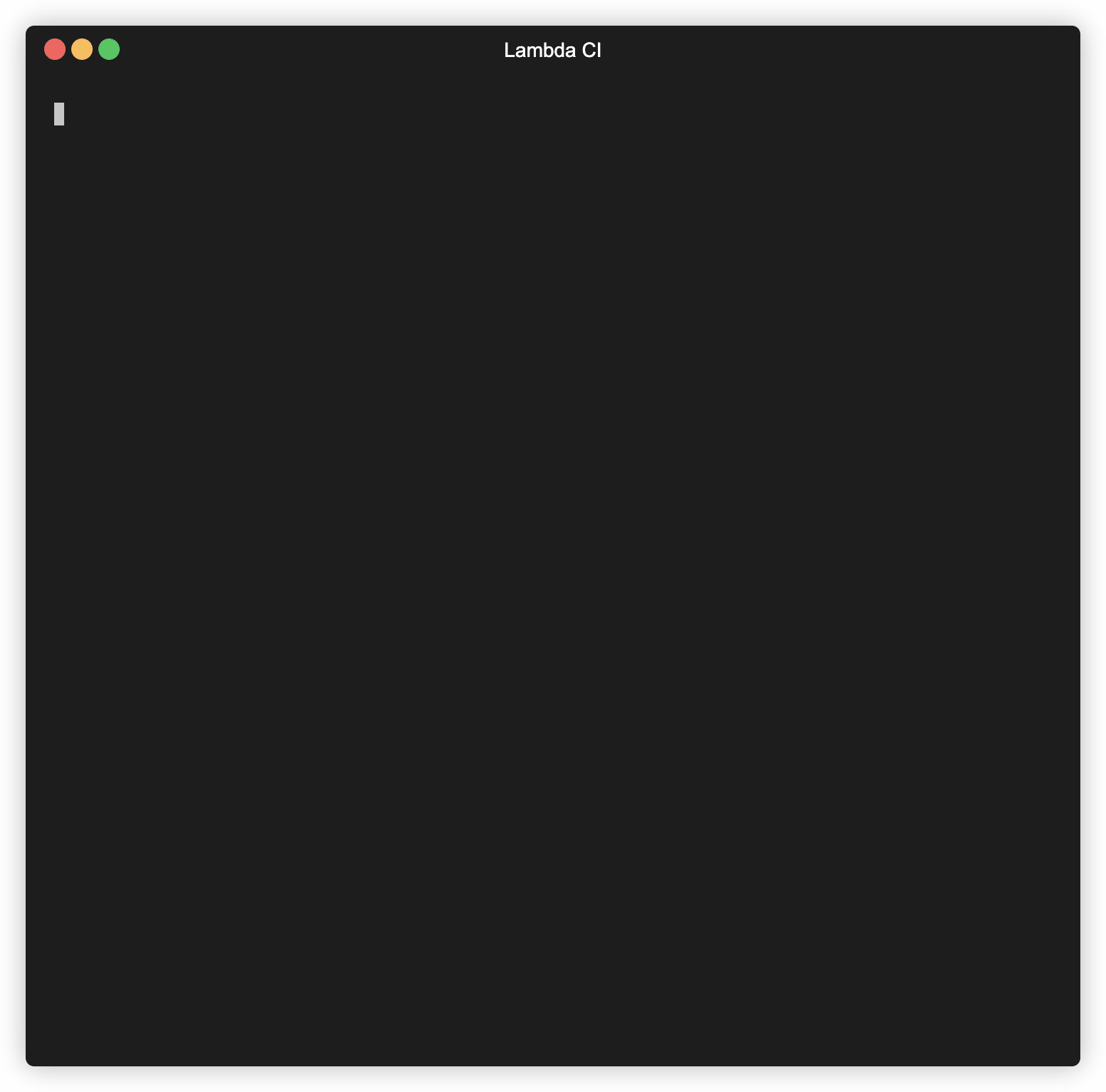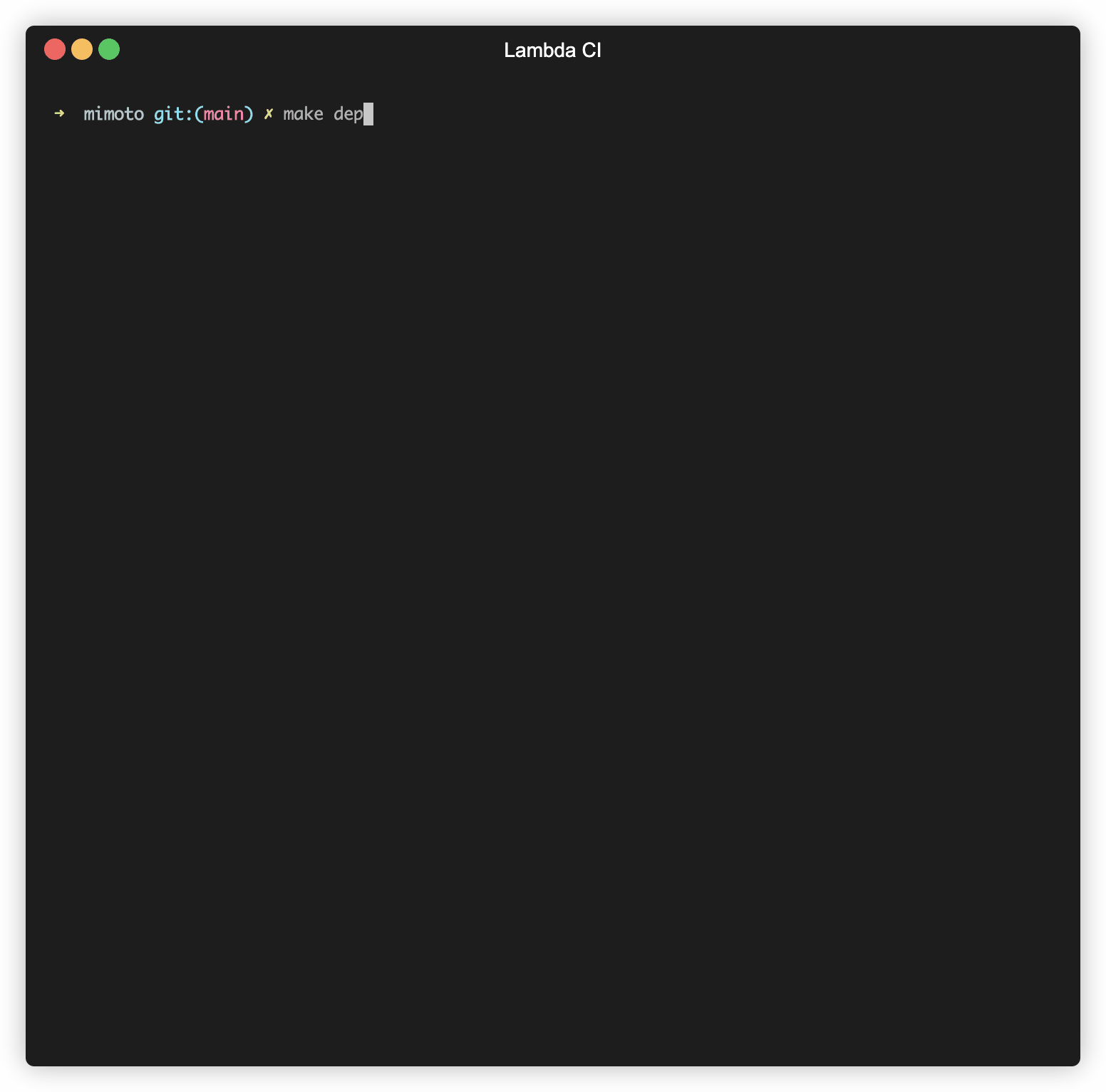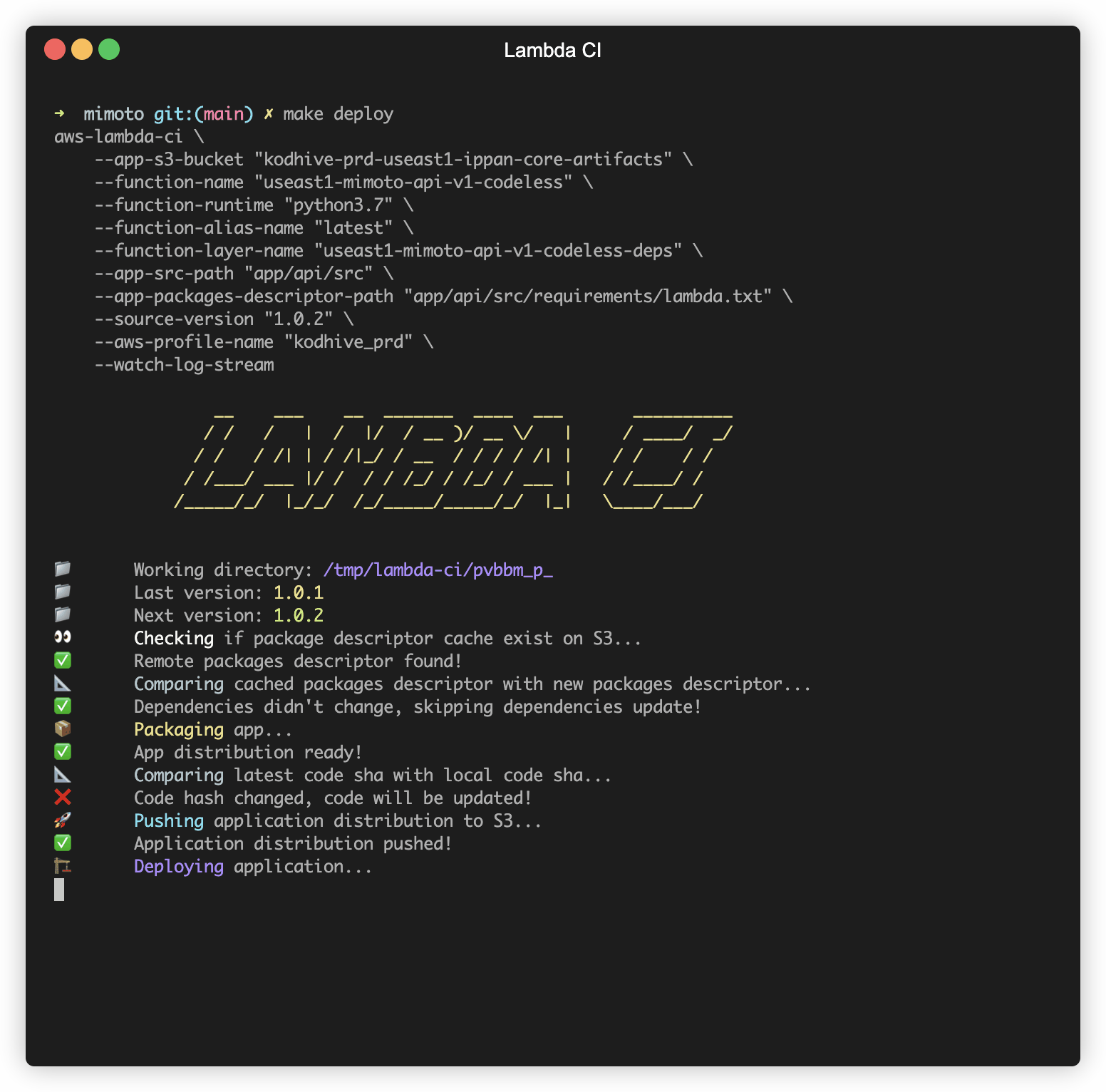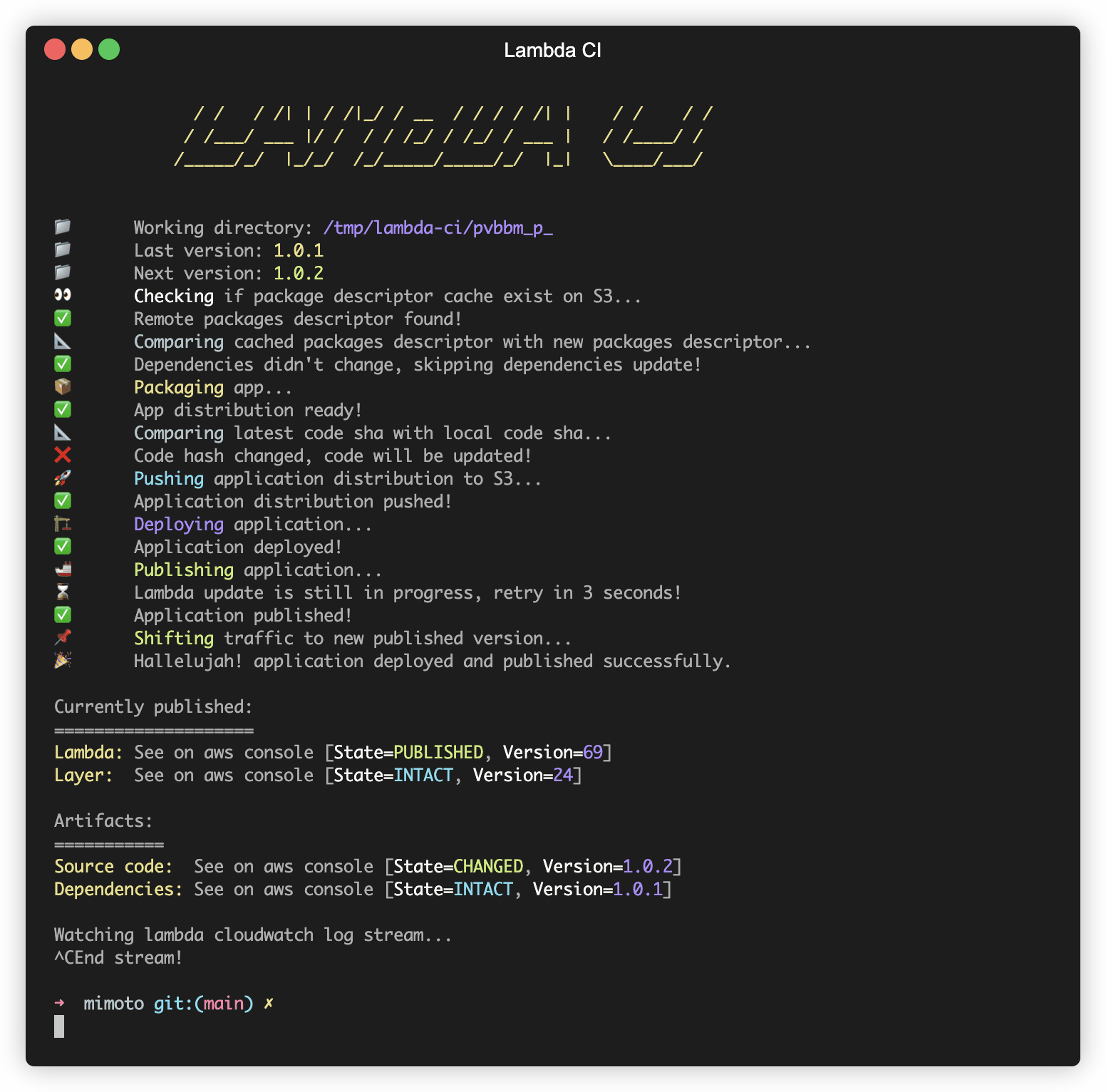
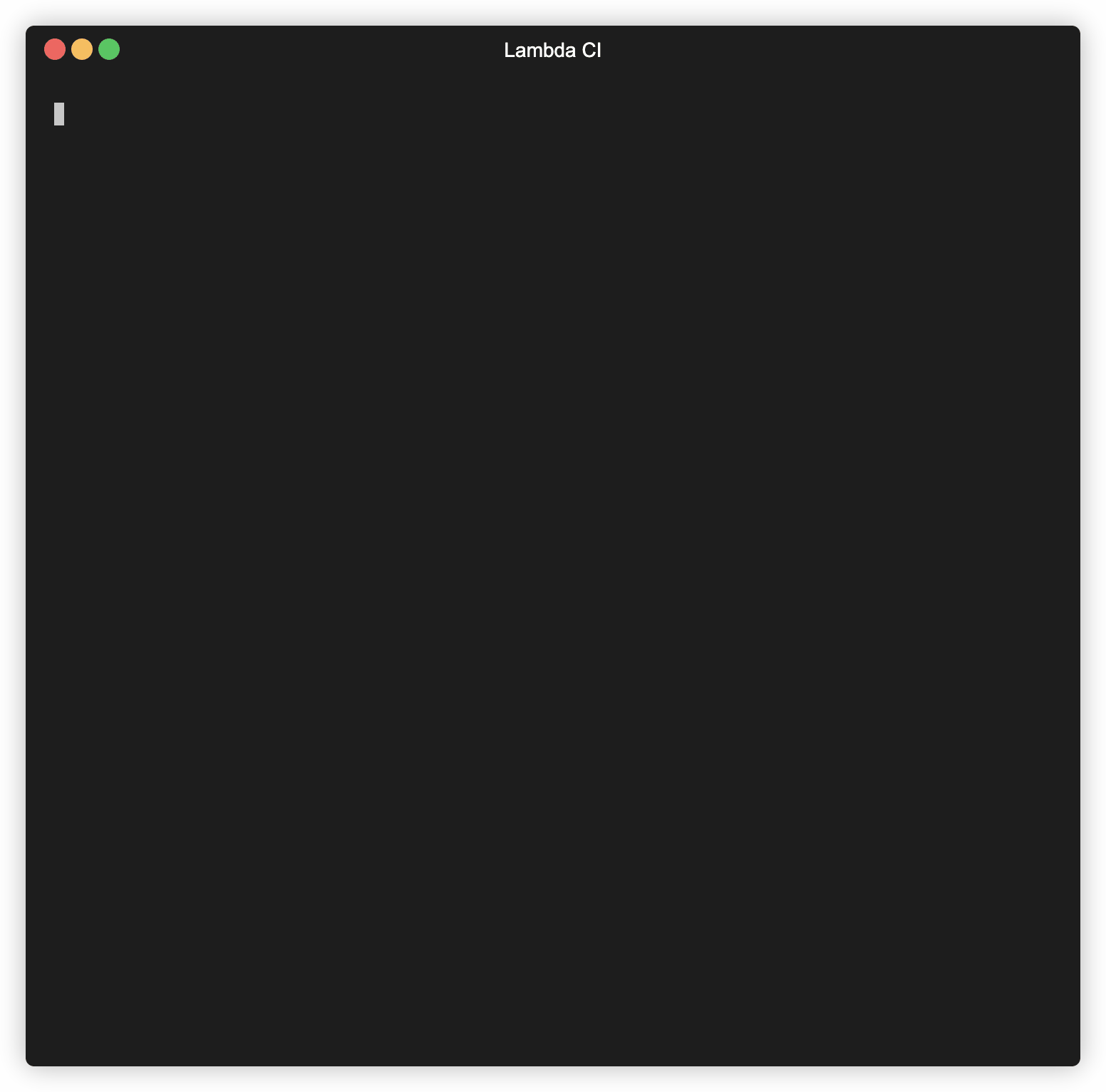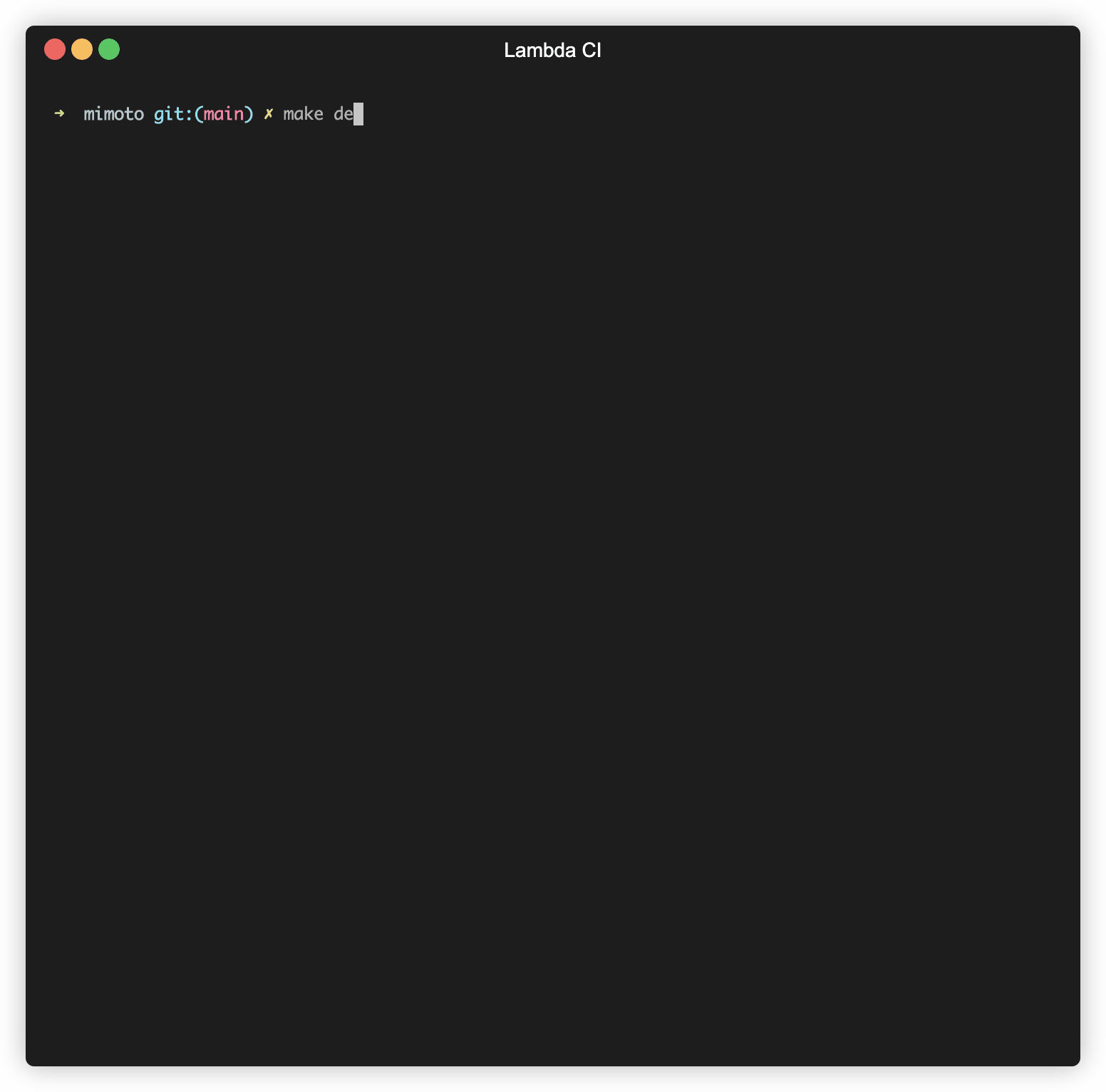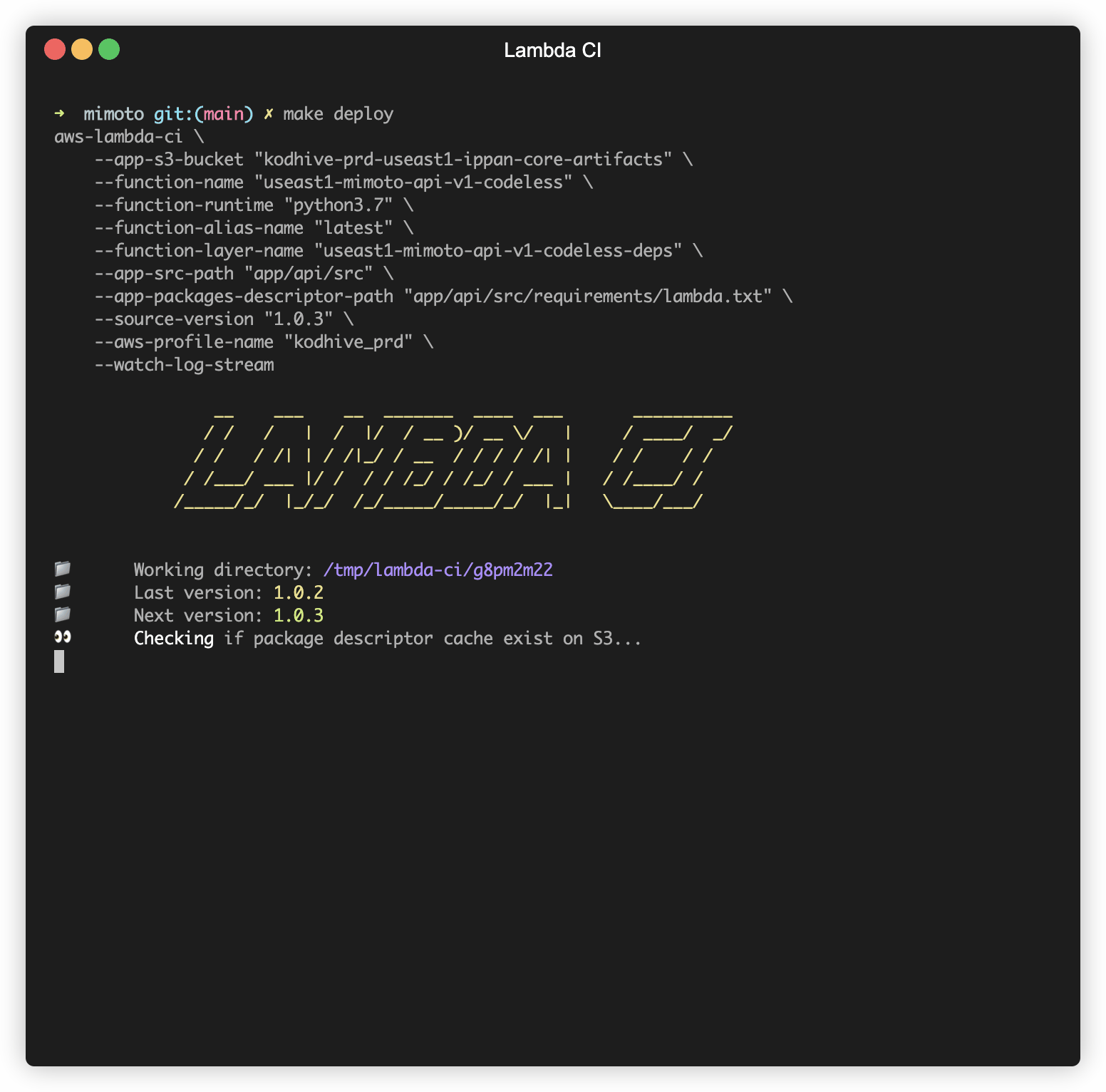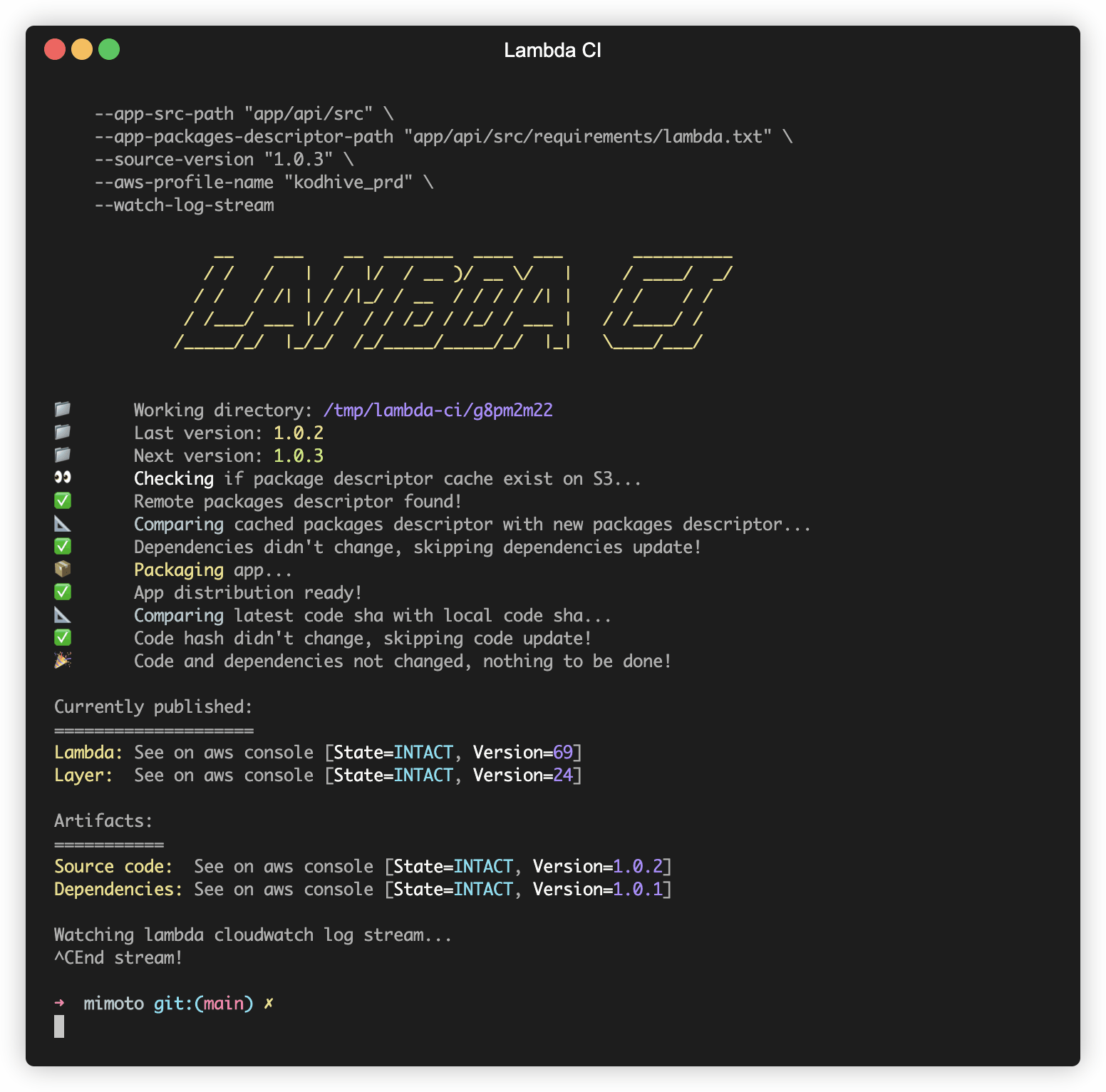
Code and dependencies changed
If both code and dependencies changed, the pipeline will publish both changes.
Just code changed
If code changed but not dependencies, the pipeline will publish new code and the dependencies will be left intact.
Nothing changed
If both code and dependencies not changed, the pipeline will not publish anything.
Leveraging codebuild/codepipeline for automated CI

After preparing the python CI package, we can now configure codebuild and codepipeline to use it.
TLDR: We've published a reusable terraform module for Lambda CI using Codepipeline/Codebuild, you can check it here.
Build specification
Let's start by creating the build specification file. It will be used by the codebuild project when the build is
triggered by codepipeline. In the install phase, we instruct codebuild to use runtimes shipped with docker.
In the pre-build phase, we get the source version that triggered the build, which can be a commit hash for pushes
events or SemVer tag for releases events and we install aws-lambda-ci.
Finally, during build phase, we call aws-lambda-ci that should take care of the next CI phases.
version: 0.2
phases:
install:
runtime-version:
docker: 19
pre_build:
commands:
- SOURCE_VERSION=$(echo $CODEBUILD_RESOLVED_SOURCE_VERSION)
- pip3 install aws-lambda-ci
build:
commands:
- |
aws-lambda-ci \
--source-version "$SOURCE_VERSION" \
--function-name "$FUNCTION_NAME" \
--function-runtime "$FUNCTION_RUNTIME" \
--function-alias-name "$FUNCTION_ALIAS_NAME" \
--function-layer-name "$FUNCTION_NAME-deps" \
--app-s3-bucket "$APP_S3_BUCKET" \
--app-src-path "$APP_SRC_PATH" \
--app-packages-descriptor-path "$APP_PACKAGES_DESCRIPTOR_PATH"
Codebuild
After preparing the build specification file, we can now pass it to codebuild project along with environment variables
that will be forwarded to aws-lambda-ci.
It's important to set the source to CODEPIPELINE as codepipeline will trigger the codebuild project in response
to Github webhook and will prevent concurrent builds that can cause issues during deployment.
resource "aws_codebuild_project" "default" {
name = local.prefix
description = "Build ${var.github_repository.branch} of ${var.github_repository.name} and deploy"
build_timeout = var.build_timeout
service_role = aws_iam_role.role.arn
source {
type = "CODEPIPELINE"
buildspec = file("${path.module}/templates/buildspec.yml")
}
artifacts {
type = "CODEPIPELINE"
}
cache {
type = "LOCAL"
modes = ["LOCAL_DOCKER_LAYER_CACHE"]
}
environment {
compute_type = var.compute_type
image = var.image
type = var.type
privileged_mode = var.privileged_mode
# Bucket
# ------
environment_variable {
name = "APP_S3_BUCKET"
value = var.s3_artifacts.bucket
}
# Build
# -----
environment_variable {
name = "APP_SRC_PATH"
value = var.app_src_path
}
environment_variable {
name = "APP_PACKAGES_DESCRIPTOR_PATH"
value = var.packages_descriptor_path
}
# Function
# --------
environment_variable {
name = "FUNCTION_NAME"
value = var.lambda.name
}
environment_variable {
name = "FUNCTION_RUNTIME"
value = var.lambda.runtime
}
environment_variable {
name = "FUNCTION_ALIAS_NAME"
value = var.lambda.alias
}
environment_variable {
name = "FUNCTION_LAYER_NAME"
value = "${var.lambda.name}-deps"
}
}
tags = local.common_tags
}
Codepipeline
Now that we have prepared the codebuild project, we will create the pipeline that will orchestrate the CI runs/stages.
During Source stage, we set up codepipeline to detect any change to target git branch if the environment is a
pre-release like qa or staging, checkout the lambda git repository and send it to next stage through
artifacts bucket.
In BuildAndDeploy stage, codepipeline will trigger codebuild and wait for codebuild execution to deploy and
publish the lambda function.
resource "aws_codepipeline" "default" {
name = local.prefix
role_arn = aws_iam_role.role.arn
##########################
# Artifact Store S3 Bucket
##########################
artifact_store {
location = var.s3_artifacts.bucket
type = "S3"
}
#########################
# Pull source from Github
#########################
stage {
name = "Source"
action {
name = "Source"
category = "Source"
owner = "AWS"
provider = "CodeStarSourceConnection"
version = "1"
output_artifacts = ["code"]
configuration = {
FullRepositoryId = "${var.github.owner}/${var.github_repository.name}"
BranchName = var.github_repository.branch
DetectChanges = var.pre_release
ConnectionArn = var.github.connection_arn
OutputArtifactFormat = "CODEBUILD_CLONE_REF"
}
}
}
#########################
# Build & Deploy to S3
#########################
stage {
name = "BuildAndDeploy"
action {
name = "BuildAndDeploy"
category = "Build"
owner = "AWS"
provider = "CodeBuild"
input_artifacts = ["code"]
output_artifacts = ["package"]
version = "1"
configuration = {
ProjectName = var.codebuild_project_name
}
}
}
}
Release webhook
To support triggering the pipeline in response to github releases, we have to configure webhook resources that will only
be created if var.pre_release is set to false.
# Webhooks (Only for github releases)
resource "aws_codepipeline_webhook" "default" {
count = var.pre_release ? 0:1
name = local.prefix
authentication = "GITHUB_HMAC"
target_action = "Source"
target_pipeline = aws_codepipeline.default.name
authentication_configuration {
secret_token = var.github.webhook_secret
}
filter {
json_path = "$.action"
match_equals = "published"
}
}
resource "github_repository_webhook" "default" {
count = var.pre_release ? 0:1
repository = var.github_repository.name
configuration {
url = aws_codepipeline_webhook.default.0.url
secret = var.github.webhook_secret
content_type = "json"
insecure_ssl = true
}
events = [ "release" ]
}
Slack Notifications
To receive slack alerts for pipeline's failure and success events, we will add two notification rules. the
first one will notify started and succeeded events and the second will notify failure events.
resource "aws_codestarnotifications_notification_rule" "notify_info" {
name = "${local.prefix}-info"
resource = aws_codepipeline.default.arn
detail_type = "FULL"
status = "ENABLED"
event_type_ids = [
"codepipeline-pipeline-pipeline-execution-started",
"codepipeline-pipeline-pipeline-execution-succeeded"
]
target {
type = "AWSChatbotSlack"
address = "${local.chatbot}/${var.ci_notifications_slack_channels.info}"
}
}
resource "aws_codestarnotifications_notification_rule" "notify_alert" {
name = "${local.prefix}-alert"
resource = aws_codepipeline.default.arn
detail_type = "FULL"
status = "ENABLED"
event_type_ids = [
"codepipeline-pipeline-pipeline-execution-failed",
]
target {
type = "AWSChatbotSlack"
address = "${local.chatbot}/${var.ci_notifications_slack_channels.alert}"
}
}
Put it all together

We can structure the CI components into two modules, one for the build and another for the pipeline.
module "code_build_project" {
source = "../../components/build"
prefix = local.prefix
common_tags = var.common_tags
# S3
s3_artifacts = var.s3_artifacts
lambda = var.lambda
# App
app_src_path = var.app_src_path
packages_descriptor_path = var.packages_descriptor_path
# Github
connection_arn = var.github.connection_arn
github_repository = var.github_repository
}
module "code_pipeline_project" {
source = "../../components/pipeline"
prefix = local.prefix
common_tags = local.common_tags
# Github
github = var.github
pre_release = var.pre_release
github_repository = var.github_repository
# S3
s3_artifacts = var.s3_artifacts
# Codebuild
codebuild_project_name = module.code_build_project.codebuild_project_name
ci_notifications_slack_channels = var.ci_notifications_slack_channels
}
Finally, we will wrap the two modules into a single module and call it like this.
module "lambda_ci" {
source = "git::https://github.com/obytes/terraform-aws-lambda-ci.git//modules/ci"
prefix = "demo-api-ci"
common_tags = {env = "test", stack = "demos-ci"}
lambda = module.lambda.lambda
app_src_path = "src"
packages_descriptor_path = "requirements.txt"
# Github
s3_artifacts = {
arn = aws_s3_bucket.artifacts.arn
bucket = aws_s3_bucket.artifacts.bucket
}
pre_release = true
github = {
owner = "obytes"
token = "gh_123456789876543234567845678"
webhook_secret = "not-secret"
connection_arn = "[GH_CODESTAR_CONNECTION_ARN]"
}
github_repository = {
name = "demo-api"
branch = "main"
}
# Notifications
ci_notifications_slack_channels = {
info = "ci-info"
alert = "ci-alert"
}
}
What's next?
Now that we have implemented our Lambda CI reusable pipeline, in the next part we will use it to deploy nodejs and flask APIs.
Share the article if you find it useful! See you next time.



